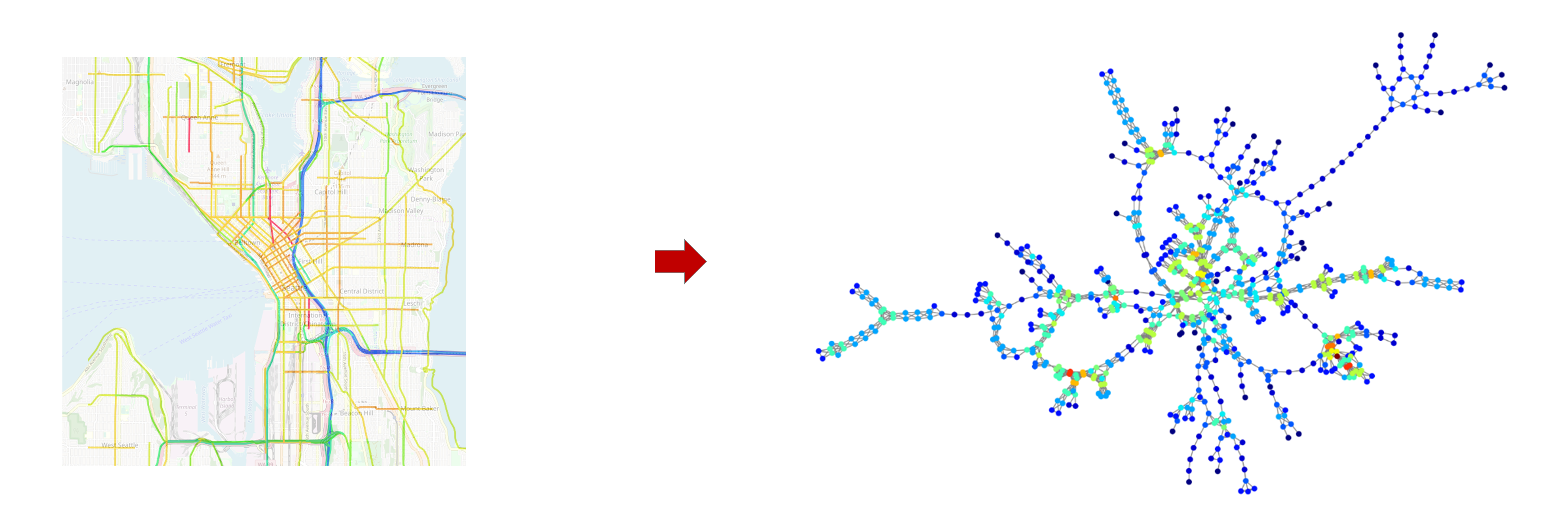
This is a post introducing a Graph Markov Network structure for dealing with spatial-temporal data forecasting with missing values.
Traffic forecasting is a classical task for traffic management and it plays an important role in intelligent transportation systems. However, since traffic data are mostly collected by traffic sensors or probe vehicles, sensor failures and the lack of probe vehicles will inevitably result in missing values in the collected raw data for some specific links in the traffic network.
A traffic network normally consists of multiple roadway links. The traffic forecasting task targets to predict future traffic states of all (road) links or sensor stations in the traffic network based on historical traffic state data. The collected spatial-temporal traffic state data of a traffic network with links/sensor-stations can be characterized as a -step sequence , in which demonstrates the traffic states of all links at the -th step. The traffic state of the -th link at time is represented by .
Here, the superscript of a traffic state represents the spatial dimension and the subscript denotes the temporal dimension.
Problem Definition
Traffic Forecasting
The short-term traffic forecasting problem can be formulated as, based on -step historical traffic state data, learning a function to generate the traffic state at next time step (single-step forecasting) as follows:
Learning Traffic Network as a Graph
Since the traffic network is composed of road links and intersections, it is intuitive to consider the traffic network as an undirected graph consisting of vertices and edges. The graph can be denoted as :
- : a set of vertices .
- : a set of edges connecting vertices.
- : an adjacency matrix, a symmetric (typically sparse) adjacency matrix with binary elements, in which denotes the connectedness between nodes and .
- To characterize the vertices’ self-connectedness, a self-connection adjacency matrix is denoted as , i.e. , implying each vertex in the graph is self-connected. Here, is an identity matrix.
- Based on , a graph degree matrix () describing the number of edges attached to each vertex can be obtained by .
- The connectedness of the graph vertices can also be encoded by the Laplacian matrix (), which is essential for spectral graph analysis. The combinatorial Laplacian matrix is defined as , and the normalized definition is . Since is a symmetric positive semi-definite matrix, it can be diagonalized as by its eigenvector matrix , where and is the corresponding diagonal eigenvalue matrix satisfying .
Given the graph representation of the traffic network, the traffic forecasting problem can be reformulated as
Traffic Forecasting with Missing Values
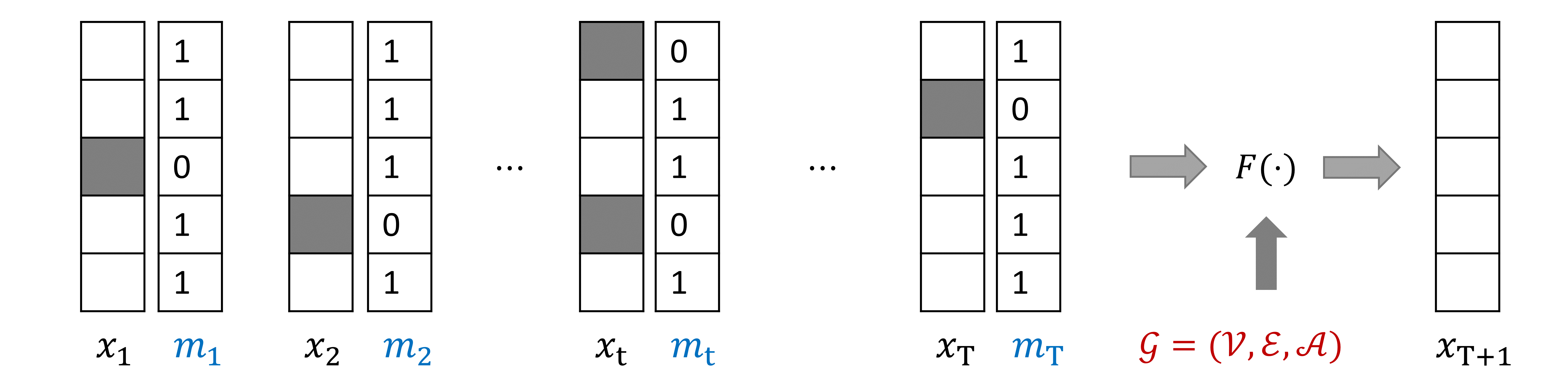
Traffic state data can be collected by multi-types of traffic sensors or probe vehicles. When traffic sensors fail or no probe vehicles go through road links, the collected traffic state data may have missing values. We use a sequence of masking vectors , where , to indicate the position of the missing values in traffic state sequence . If is observed , otherwise .
Taking the missing values into consideration, we can formulate the traffic forecasting problem as follows
Graph Markov Process
A traffic network is a dynamic system and the states on all links keep varying resulted by the movements of vehicles in the system. We assume teh transitions of traffic states have two properties
Markov Property: The future state of the traffic network depends only upon the present state , not on the sequence of states that preceded it. Taking as random variables with the Markov property and as the observed traffic states. The Markov process can be formulated in a conditional probability form as
where demonstrates the probability. It can be formulated in the vector form as
where is the transition matrix and measures how much influence has on forming the state .
The time interval between two consecutive time steps of traffic states will affect the transition process. Thus, a decay parameter is multiplied to represent the temporal impact on transition process as
Graph Localization Property: We assume traffic state of a link 𝑠 is mostly influenced by itself and neighboring links. This property can be formulated in a conditional probability form as
where the superscripts and are the indices of graph links (road links). The denotes a set of one-hop neighboring links of link and link itself. Its vector form can easily represented by
Graph Markov Process: By incorporating the Markov property and the graph localization property, the traffic state transition process is defined as a graph Markov process (GMP) formulated in the vector form as
where is the Hadamard (element-wise) product operator that .
Handling Missing Values in Graph Markov Process
As we assume the traffic state transition process follows the graph Markov process, the future traffic state can be inferred by the present state. If there are missing values in the present state, we can infer the missing values from previous states.
A completed state is denoted by , in which all missing values are filled based on historical data. The completed state consists of two parts, the observed state values and the inferred state values:
where is the inferred part. Because ,
Since the transition of completed states follows the the graph Markov process, . For simplicity, the graph Markov transition matrix is denoted by , i.e. . Hence, the transition process of completed states can be represented as
Applying the expansion of , the transition process becomes
After iteratively applying steps of previous states from to , can be described as
The steps of historical steps of states can be written in a summation form as
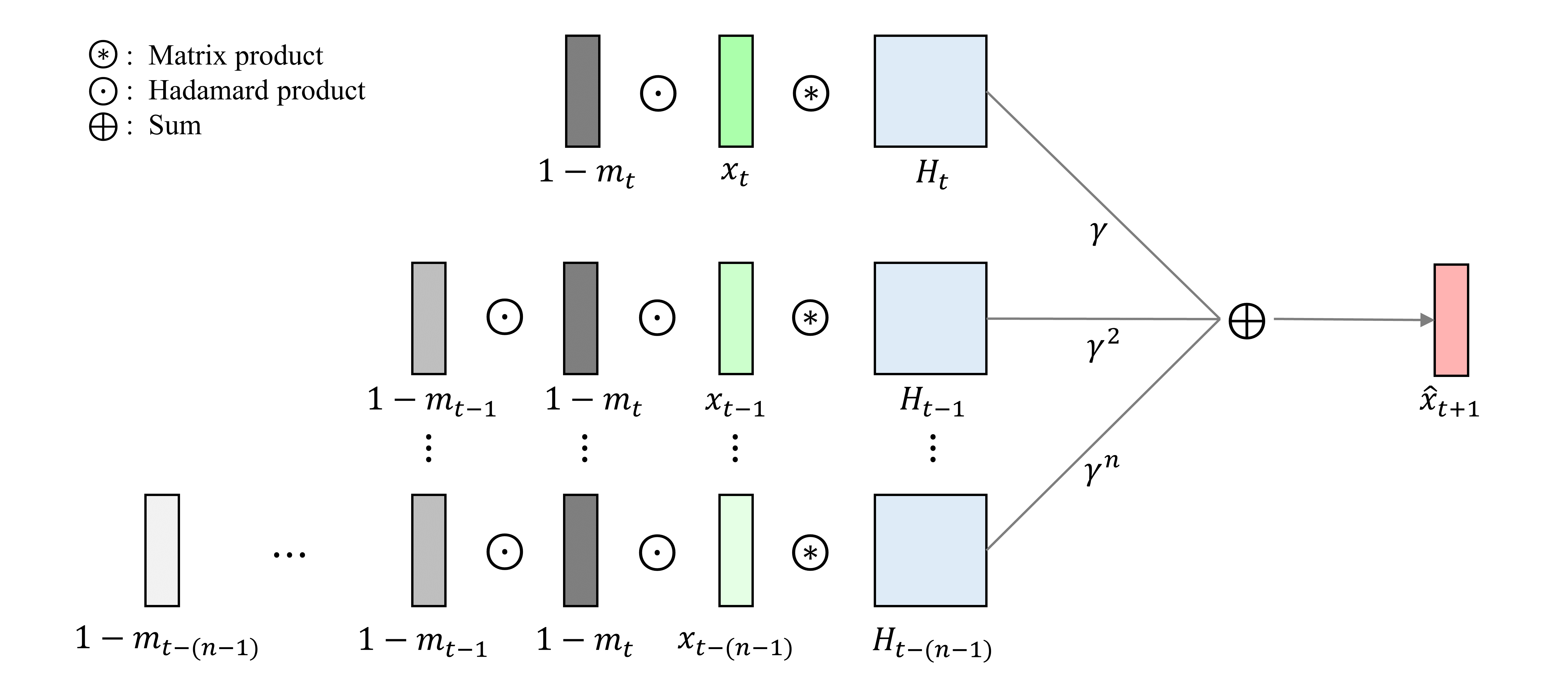
where , , and are the summation, matrix product, and Hadamard product operators, respectively. For simplicity, we denote the term with the as , and the GMP of the complected states can be represented by
When is large enough, we consider is a negligibly term.
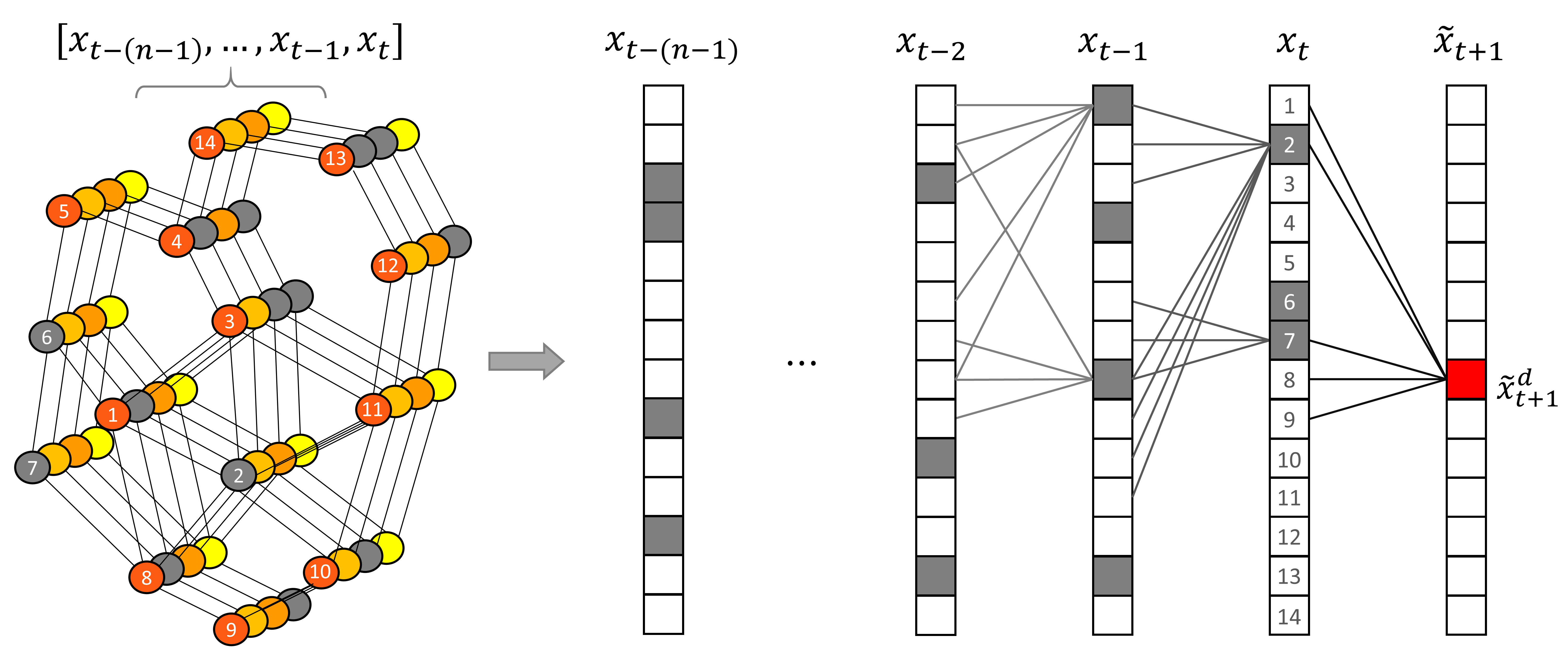
The graph Markov process can be demonstrated by the following figure. The gray-colored nodes in the left sub-figure demonstrate the nodes with missing values. Vectors on the right side represent the traffic states. The traffic states at time $t$ are numbered to match the graph and the vector. The future state (in red color) can be inferred from their neighbors in the previous steps.
Graph Markov Network
The graph Markov network (GMN) is designed based on the graph Markov process, which contains transition weight matrices. The product of the these matrices measures the contribution of for generating the . To reduce matrix product operations and at the same time keep the learning capability in the GMP, is simplified into , where is a weight matrix. In this way, can directly measure the contribution of for generating the and skip the intermediate state transition processes. Further, the GMP still has weight matrices (), and thus, the learning capability in terms of the size of parameters does not change. The benefits of the simplification is that the GMP can reduce times of multiplication between two matrices in total. The is considered small enough and omitted for simplicity.
Based on the GMP and the aforementioned simplification, the Graph Markov Network for traffic forecasting with missing values can be defined as
where is the predicted traffic state for the future time step and are the model’s weight matrices that can be learned and updated during the training process.
Structure of the graph Markov network is shown below. Here, .
Code
The code for implementing the GMN is published in this GitHub Repo. 
Reference
For more details of the model and experimental results, please refer to
[1] Zhiyong Cui, et al. Graph markov network for traffic forecasting with missing data. Transportation Research Part C: Emerging Technologies, 2020. [arXiv]